How Node.js Handles Multiple Requests with a Single Thread

Node.js runs on a single thread. This seems impossible. How can one thread handle thousands of requests? The answer is the event loop and a clever design pattern. Understand this and Node.js's power becomes obvious.
This is about how Node.js handles concurrency, the event loop, background workers, and why a single-threaded language can scale to handle massive workloads.
The Single-Threaded Nature of Node.js
JavaScript code in Node.js runs on a single thread. Your application code executes one line at a time, in order.
One Thread, One Stack, One Job at a Time
Your JavaScript Code
↓
Single Thread
↓
One statement at a time
↓
Next statement runs when previous finishes
console.log("1");
console.log("2");
console.log("3");
// Output:
// 1
// 2
// 3
The thread processes each line sequentially.
Single-Threaded Means What, Exactly?
function task1() {
console.log("Task 1 starting");
for (let i = 0; i < 1000000000; i++) {} // Long operation
console.log("Task 1 done");
}
function task2() {
console.log("Task 2 starting");
console.log("Task 2 done");
}
task1();
task2();
// Output:
// Task 1 starting
// Task 1 done
// Task 2 starting
// Task 2 done
Task 2 has to wait for Task 1 to finish. The single thread blocks. It can't do anything else until Task 1 completes.
This is a problem in a web server. If one request takes 10 seconds, all other requests wait 10 seconds.
So How Does Node.js Handle Multiple Requests?
The trick is: Node.js doesn't actually execute multiple JavaScript operations simultaneously. Instead, it cleverly switches between them using the event loop and delegates heavy work to background threads.
Understanding Concurrency vs Parallelism
These terms sound similar but are fundamentally different.
Parallelism: True Simultaneous Execution
Multiple tasks run at the exact same time on different CPU cores.
Core 1: Task A --------→
Core 2: Task B --------→
Core 3: Task C --------→
All three run simultaneously
Two multi-core processors can do parallel tasks. Node.js on a single thread cannot.
Concurrency: Interleaved Execution
One thread rapidly switches between tasks, making it appear like they run simultaneously.
Thread: Task A → Task B → Task A → Task C → Task B → Task C → ...
Switching so fast it looks like they're all running at once
Node.js does this. It's not true simultaneous execution, but it feels like it to the user.
The Analogy: Chef Handling Orders
Imagine a restaurant with one chef.
Parallel: Multiple chefs cooking different dishes at the same time.
Concurrent: One chef:
- Starts cooking an order (put it on the stove)
- While it's cooking, takes the next order
- While that's cooking, preps a third order
- Checks on the first dish (it's done, plate it)
- Gets the second dish, plates it
- Continues cooking the third dish
- Repeats
The chef isn't cooking multiple dishes at once. But orders are being prepared concurrently. The chef switches between tasks during downtime.
Node.js is the chef. Your requests are orders. The event loop manages the switching.
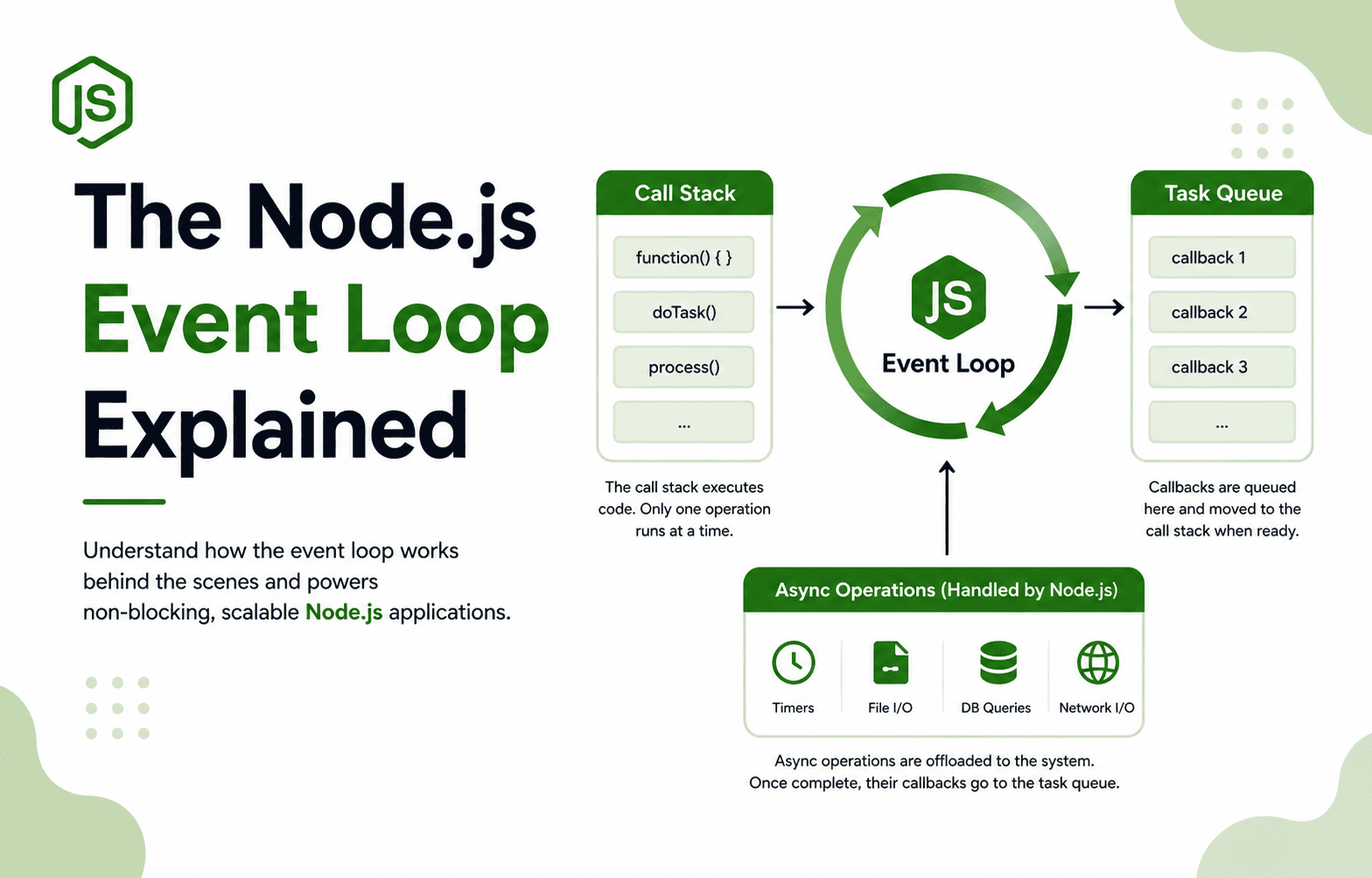
The Event Loop: The Brain of Node.js
The event loop is what makes concurrency possible. It's the mechanism that keeps Node.js running and switching between tasks.
What Is the Event Loop?
The event loop continuously checks for work to do. It runs through different types of tasks in a specific order.
Event Loop Phases (simplified):
1. Timers → Execute setTimeout/setInterval callbacks
2. Pending I/O → Execute I/O operations
3. Check → Execute setImmediate callbacks
4. Close → Execute cleanup callbacks
When all phases are empty, loop repeats
How It Works
console.log("Start");
setTimeout(function() {
console.log("After 0ms");
}, 0);
console.log("End");
// Output:
// Start
// End
// After 0ms
Here's what happens:
1. console.log("Start") runs immediately
Output: Start
2. setTimeout() registers the callback but doesn't execute it
The callback is added to the event loop queue
3. console.log("End") runs immediately
Output: End
4. The main JavaScript code is done
5. Event loop checks its queues
It finds the setTimeout callback
6. Event loop executes the callback
Output: After 0ms
The callback runs later, not immediately. The event loop scheduled it.
Event Loop Keeps Running
const http = require("http");
const server = http.createServer((req, res) => {
res.writeHead(200);
res.end("Hello");
});
server.listen(3000);
console.log("Server listening on port 3000");
Output: Server listening on port 3000
Then the program doesn't exit. The server stays running. Why? The event loop is still running, waiting for requests. When a request comes in, it handles it. When done, it goes back to waiting.
The event loop never stops (until you kill the process).
The Event Loop Executes Your Code
While (event loop is running) {
if (timers have callbacks) {
execute timer callbacks
}
if (I/O operations are done) {
execute I/O callbacks
}
if (setImmediate has callbacks) {
execute setImmediate callbacks
}
Wait for more events
}
This loop runs constantly, even when nothing is happening (it just waits).
Handling Multiple Requests with One Thread
Now let's see how multiple HTTP requests are handled.
Single-Threaded HTTP Server
const http = require("http");
const server = http.createServer((req, res) => {
console.log("Request received");
// Simulate some work
for (let i = 0; i < 100000000; i++) {}
res.writeHead(200);
res.end("Hello");
});
server.listen(3000);
A request comes in. The callback runs. It does some work. It sends a response. Done.
But what if 5 requests come in simultaneously?
Request 1 Timeline
Time: 0ms → Request 1 arrives
Time: 0ms → Callback runs
Time: 0-100ms → Doing work
Time: 100ms → Response sent
Requests 2-5 Arrive While Request 1 Is Processing
Time: 0ms → Request 1 arrives → Callback queued
Time: 10ms → Request 2 arrives → Queued
Time: 20ms → Request 3 arrives → Queued
Time: 30ms → Request 4 arrives → Queued
Time: 40ms → Request 5 arrives → Queued
Time: 100ms → Request 1 processing done → Response sent
Time: 100ms → Request 2 callback runs
Time: 200ms → Request 2 done → Response sent
Time: 200ms → Request 3 callback runs
...and so on
Requests queue up. They're handled one at a time. This seems bad. But here's the trick: the waiting is hidden.
The Real Trick: Non-Blocking I/O
The problem above assumes blocking work (the for loop). In real applications, work is I/O (network, files, database):
const http = require("http");
const fs = require("fs");
const server = http.createServer((req, res) => {
// Non-blocking I/O
fs.readFile("data.txt", (err, data) => {
res.writeHead(200);
res.end(data);
});
});
server.listen(3000);
This is what happens:
Time: 0ms → Request 1 arrives
Time: 0ms → fs.readFile() called (non-blocking)
→ Callback registered in event loop
→ Function returns immediately
Time: 0ms → Event loop is free!
→ Can handle Request 2
Time: 0ms → Request 2 arrives
Time: 0ms → fs.readFile() called (non-blocking)
→ Callback registered
→ Returns immediately
Time: 0ms → Event loop is free!
→ Waiting for I/O to complete
Time: 50ms → File read completes for Request 1
→ Callback for Request 1 executes
→ Response sent
Time: 50ms → Event loop is free!
→ Waiting for Request 2's file read
Time: 100ms → File read completes for Request 2
→ Callback for Request 2 executes
→ Response sent
Two requests are handled "concurrently" but with no blocking. While one is waiting for file I/O, the other can start.
Delegating Work to Background Threads
Some work can't be non-blocking (CPU-intensive tasks). For this, Node.js uses the Worker Thread Pool.
CPU-Intensive Work Blocks the Thread
function expensiveCalculation() {
let total = 0;
for (let i = 0; i < 10000000000; i++) {
total += i;
}
return total;
}
const result = expensiveCalculation();
console.log(result);
This takes 10 seconds. During those 10 seconds, Node.js can't handle any requests. It's blocked.
Delegating to Worker Threads
Node.js has a Worker Thread Pool (libuv). You can delegate heavy work:
const { Worker } = require("worker_threads");
const http = require("http");
const server = http.createServer((req, res) => {
// Delegate to a worker thread
const worker = new Worker("./worker.js");
worker.on("message", (result) => {
res.writeHead(200);
res.end("Result: " + result);
});
});
server.listen(3000);
The worker thread does the heavy calculation in the background. The main thread remains free to handle other requests.
What Gets Delegated?
By default, Node.js delegates some I/O operations to the worker thread pool:
File I/O (fs module) → Worker threads
DNS lookups → Worker threads
Some crypto operations → Worker threads
Database connections → Often delegated
Your JavaScript code → Main thread
When you call fs.readFile(), it doesn't block the main thread. It's delegated to a worker thread. The worker reads the file. When done, the callback is queued in the event loop.
libuv: The Magic Behind the Scenes
libuv is a C library that Node.js uses. It manages:
- The event loop
- The worker thread pool (usually 4 threads by default)
- Platform-specific APIs for file I/O, networking, etc.
Node.js Application
↓
libuv (Event Loop + Thread Pool)
↓
Operating System APIs
↓
Hardware (CPU, Disk, Network)
The Complete Picture: How a Request Is Handled
Let's trace a real HTTP request from start to finish.
Request Handling Flow
1. Request arrives at the server
↓
2. Event loop detects it
↓
3. Callback function (request handler) queued
↓
4. Event loop executes the callback
↓
5. Callback calls fs.readFile() (or other I/O)
↓
6. fs.readFile() is delegated to worker thread
Callback is registered
↓
7. Event loop is free, returns to waiting
↓
8. Worker thread reads file from disk
↓
9. File reading completes
↓
10. Callback is queued in event loop
↓
11. Event loop executes the callback
↓
12. Response is sent
↓
13. Connection closed
Code Representation
const http = require("http");
const fs = require("fs");
http.createServer((req, res) => {
// Step 4: Callback runs
console.log("Request received");
// Step 5-6: Delegate file reading
fs.readFile("data.txt", (err, data) => {
// Step 11-12: Callback runs when file is read
res.writeHead(200);
res.end(data);
});
// Step 7: Function returns, thread is free
}).listen(3000);
// Step 1-2-3: Event loop waits for requests
Multiple Requests Timeline
Request 1 arrives → Handler queued
Handler runs → fs.readFile delegated to worker
→ Handler returns (thread free)
Request 2 arrives → Handler queued
Handler runs → fs.readFile delegated to worker
→ Handler returns (thread free)
Request 3 arrives → Handler queued
Handler runs → fs.readFile delegated to worker
→ Handler returns (thread free)
(Meanwhile, workers are reading files)
Worker 1: File 1 done → Callback queued
Worker 2: File 2 done → Callback queued
Worker 3: File 3 done → Callback queued
Event loop: Execute callbacks
Callback 1 → Send Response 1
Callback 2 → Send Response 2
Callback 3 → Send Response 3
Three requests are handled concurrently. The main thread never blocks. Workers handle I/O in parallel.
Why Node.js Scales Well
Efficient Resource Usage
Traditional servers create one thread per request:
Request 1 → Thread 1 (dedicated)
Request 2 → Thread 2 (dedicated)
Request 3 → Thread 3 (dedicated)
...
Request 1000 → Thread 1000 (dedicated)
Memory usage: 1000 threads × memory per thread = a lot of memory
Node.js handles all requests with one thread:
Request 1 → Event Loop
Request 2 → Event Loop
Request 3 → Event Loop
...
Request 1000 → Event Loop
Memory usage: 1 thread + small queues = much less memory
Handling C10K Problem
The C10K problem: How to handle 10,000 concurrent connections?
Traditional threaded servers struggle because:
- Creating 10,000 threads uses massive memory
- Thread switching has overhead
- Each thread has a stack (memory hungry)
Node.js handles it elegantly:
- One thread handles all connections
- I/O is delegated to worker threads
- Connections are just data in memory (lightweight)
Event-Driven Architecture
Node.js is event-driven:
Something happens → Event fires → Callback runs
(non-blocking)
This is efficient. The thread doesn't wait for anything. It processes events as they arrive.
Scales Horizontally
For even better scaling, run multiple Node.js processes:
Load Balancer
↓
├─ Node.js Process 1 (Single thread)
├─ Node.js Process 2 (Single thread)
├─ Node.js Process 3 (Single thread)
└─ Node.js Process 4 (Single thread)
Requests distributed across processes
Each process handles requests with its event loop
No threads to create. No memory overhead. Clean and fast.
Common Misconceptions
Misconception 1: "Node.js Runs Everything on One Thread"
False. JavaScript code runs on one thread. But I/O operations are delegated to worker threads. Crypto, DNS, and file operations use background threads.
Misconception 2: "Node.js Can't Do Parallel Work"
False. The main thread can't run JavaScript in parallel. But libuv's worker thread pool runs I/O operations in parallel.
Misconception 3: "Node.js Can't Handle CPU-Intensive Work"
True and false. Pure JavaScript running on the main thread blocks. But you can use Worker Threads to run CPU-intensive work in parallel:
const { Worker } = require("worker_threads");
const worker = new Worker("./heavy-calculation.js");
worker.on("message", (result) => {
console.log("Result:", result);
});
// Main thread is free to handle other requests
Misconception 4: "If One Request Takes 10 Seconds, All Requests Wait"
Only if the request does CPU-intensive work on the main thread. If it does I/O (file read, database query), other requests proceed while it waits.
Practical Example: Web Server
Simple Web Server Handling Multiple Requests
const http = require("http");
const fs = require("fs");
const server = http.createServer((req, res) => {
console.log("Request:", req.url);
// Non-blocking file read
fs.readFile("data.txt", (err, data) => {
if (err) {
res.writeHead(500);
res.end("Error");
return;
}
res.writeHead(200);
res.end(data);
console.log("Response sent for:", req.url);
});
});
server.listen(3000);
console.log("Server listening on port 3000");
What Happens
Request 1 arrives
Handler runs, calls fs.readFile()
fs.readFile() delegates to worker, returns immediately
Event loop is free
Request 2 arrives
Handler runs, calls fs.readFile()
fs.readFile() delegates to worker, returns immediately
Event loop is free
Workers finish reading files
Callbacks are queued
Event loop executes callbacks
Responses are sent
All handled concurrently with one thread.
Load Test
curl http://localhost:3000 &
curl http://localhost:3000 &
curl http://localhost:3000 &
curl http://localhost:3000 &
curl http://localhost:3000 &
Send 5 requests at once. All handled concurrently. All respond quickly.
Event Loop Phases in Detail
The event loop goes through phases:
Phase 1: Timers
Execute callbacks from setTimeout() and setInterval().
setTimeout(() => {
console.log("1 second passed");
}, 1000);
Phase 2: I/O Callbacks
Execute callbacks from file reads, network operations, etc.
fs.readFile("file.txt", (err, data) => {
console.log("File read");
});
Phase 3: Check
Execute setImmediate() callbacks.
setImmediate(() => {
console.log("Immediate");
});
Phase 4: Close
Execute close callbacks from streams and connections.
connection.on("close", () => {
console.log("Connection closed");
});
The loop repeats these phases constantly.
Order Matters
setTimeout(() => console.log("timeout"), 0);
setImmediate(() => console.log("immediate"));
Promise.resolve().then(() => console.log("promise"));
// Output (usually):
// promise
// timeout
// immediate
Promises are microtasks (higher priority). They execute before the next phase.
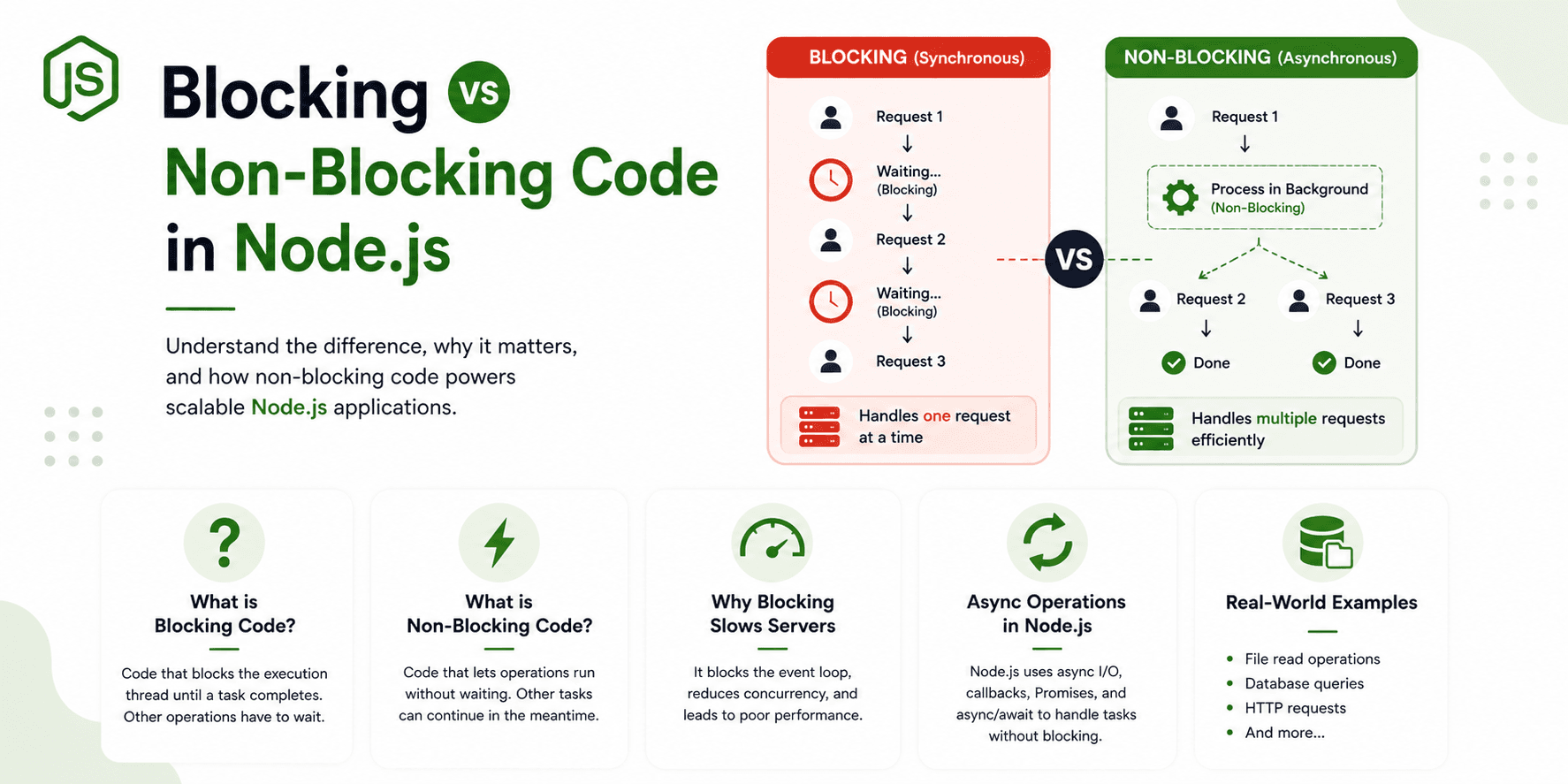
Blocking vs Non-Blocking
Understanding this distinction is crucial.
Blocking: Stops the Event Loop
const fs = require("fs");
// Blocking
const data = fs.readFileSync("file.txt");
console.log(data);
// The event loop is stopped until the file is read
Don't use Sync methods in production. They block.
Non-Blocking: Frees the Event Loop
const fs = require("fs");
// Non-blocking
fs.readFile("file.txt", (err, data) => {
console.log(data);
});
console.log("This runs before the file is read");
The callback happens later. The event loop continues.
Why Non-Blocking Matters
With blocking:
Request 1 arrives
File read (BLOCKS for 100ms)
Request 2 arrives (waits)
Request 3 arrives (waits)
File read done
Response 1 sent
Request 2 handled (BLOCKS for 100ms)
...all requests delayed
With non-blocking:
Request 1 arrives
File read starts (non-blocking)
Request 2 arrives
File read starts (non-blocking)
Request 3 arrives
File read starts (non-blocking)
Files read (in parallel)
All responses sent
Total time: ~100ms instead of 300ms
Practice Assignment
1. Understand the event loop:
console.log("1");
setTimeout(() => {
console.log("2");
}, 0);
console.log("3");
// What will the output be? Why?
2. Non-blocking file operations:
const fs = require("fs");
// Write code that:
// 1. Reads 3 files without blocking
// 2. Prints them all when done
fs.readFile("file1.txt", (err, data) => {
// Your code
});
// ... more files
3. Handle multiple HTTP requests:
const http = require("http");
const fs = require("fs");
// Create a server that:
// 1. Reads a file for each request
// 2. Sends it as response
// 3. Handles multiple requests concurrently
// Send 5 requests: curl http://localhost:3000 &
4. Identify blocking code:
// Which of these is blocking?
// A:
const data = fs.readFileSync("file.txt");
// B:
fs.readFile("file.txt", callback);
// C:
const result = expensiveCalculation();
// D:
setTimeout(callback, 0);
5. Event loop phases:
setTimeout(() => console.log("A"), 0);
setImmediate(() => console.log("B"));
process.nextTick(() => console.log("C"));
// What order will they print?
Common Mistakes
Mistake 1: Using Blocking Operations
// WRONG - blocks the event loop
const data = fs.readFileSync("file.txt");
res.end(data);
// RIGHT - non-blocking
fs.readFile("file.txt", (err, data) => {
res.end(data);
});
Mistake 2: Long-Running Synchronous Code
// WRONG - blocks for 5 seconds
for (let i = 0; i < 10000000000; i++) {}
res.end("Done");
// RIGHT - delegate to worker thread or break into chunks
Mistake 3: Misunderstanding Callback Timing
// WRONG - expecting callback to run immediately
let data;
fs.readFile("file.txt", (err, contents) => {
data = contents;
});
console.log(data); // undefined - callback hasn't run yet!
Mistake 4: Not Handling Errors in Callbacks
// WRONG - ignoring errors
fs.readFile("file.txt", (err, data) => {
console.log(data); // Crashes if error and data is undefined
});
// RIGHT - check for errors
fs.readFile("file.txt", (err, data) => {
if (err) {
console.error(err);
return;
}
console.log(data);
});
Mistake 5: Assuming One Request Blocks Others
// WRONG - thinking this blocks other requests
app.get("/slow", (req, res) => {
fs.readFile("large-file.txt", (err, data) => {
// While waiting here, other requests ARE handled
res.end(data);
});
});
// It doesn't block! Other requests proceed while this waits.
Quick Recap
Node.js runs JavaScript on a single thread. Your code executes sequentially, one statement at a time.
The event loop is what makes concurrency possible. It continuously checks for work and executes callbacks.
I/O is non-blocking. When you read a file or query a database, it's delegated to a worker thread. The main thread continues.
Concurrency vs Parallelism:
- Concurrency: One thread switches between tasks
- Parallelism: Multiple threads run simultaneously
- Node.js is concurrent (one thread) but uses parallelism for I/O
The worker thread pool (libuv) handles:
- File I/O
- DNS lookups
- Some crypto operations
- System-level I/O
Multiple requests are handled concurrently because:
- The main thread isn't blocked
- I/O operations happen in the background
- Callbacks are queued and executed when ready
Node.js scales well because:
- One thread uses less memory than many threads
- I/O is efficient (parallel in background)
- No thread creation overhead
- Can handle thousands of concurrent connections
Never block the event loop:
- Use non-blocking I/O (fs.readFile, not fs.readFileSync)
- Avoid long CPU-intensive synchronous code
- Use Worker Threads for heavy computation
The event loop has phases: Timers → I/O → Check → Close → Repeat
For true parallelism, use Worker Threads or run multiple Node.js processes.
Master the event loop and concurrency model, and you'll write scalable, efficient Node.js applications.
Happy coding! 🚀
If you enjoyed this article, check out my other blogs on this profile. 🔗 Connect with me: LinkedIn | GitHub | X (Twitter)