Inside Git: How It Works and the Role of the .git Folder
TL;DR
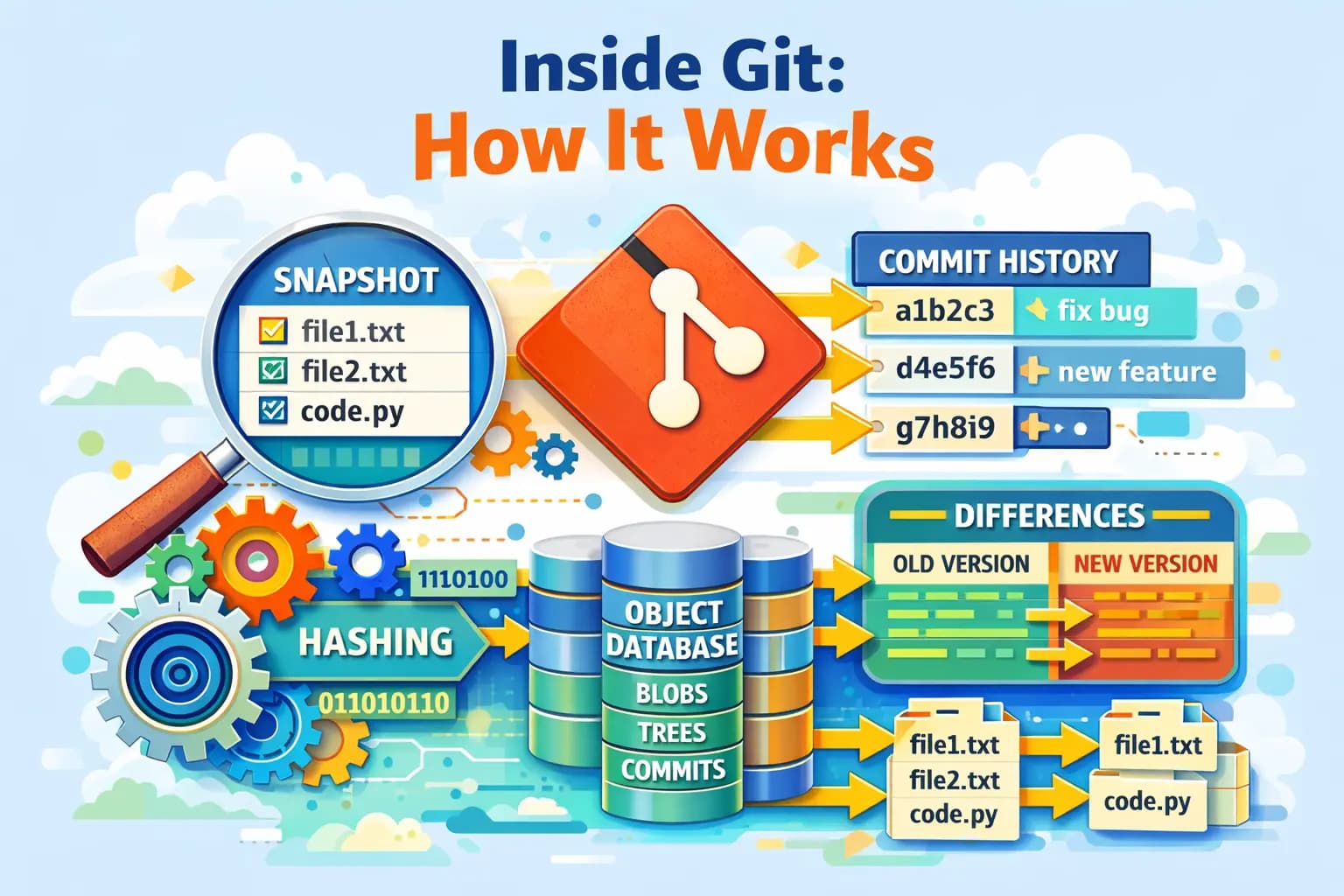
Git saves full copies of project (snapshots), not line-by-line changes.
Each version has a unique ID (hash) and is linked to the previous one.The
.gitfolder is where Git stores everything — files, history, branches, and what you’re currently working on.Git Objects contains:
Blob → file content
Tree → folders and file names
Commit → a saved version of the project + message + link to previous version
Git tracks changes by creating new objects for new content and reusing unchanged ones, then linking them together in a new commit snapshot.
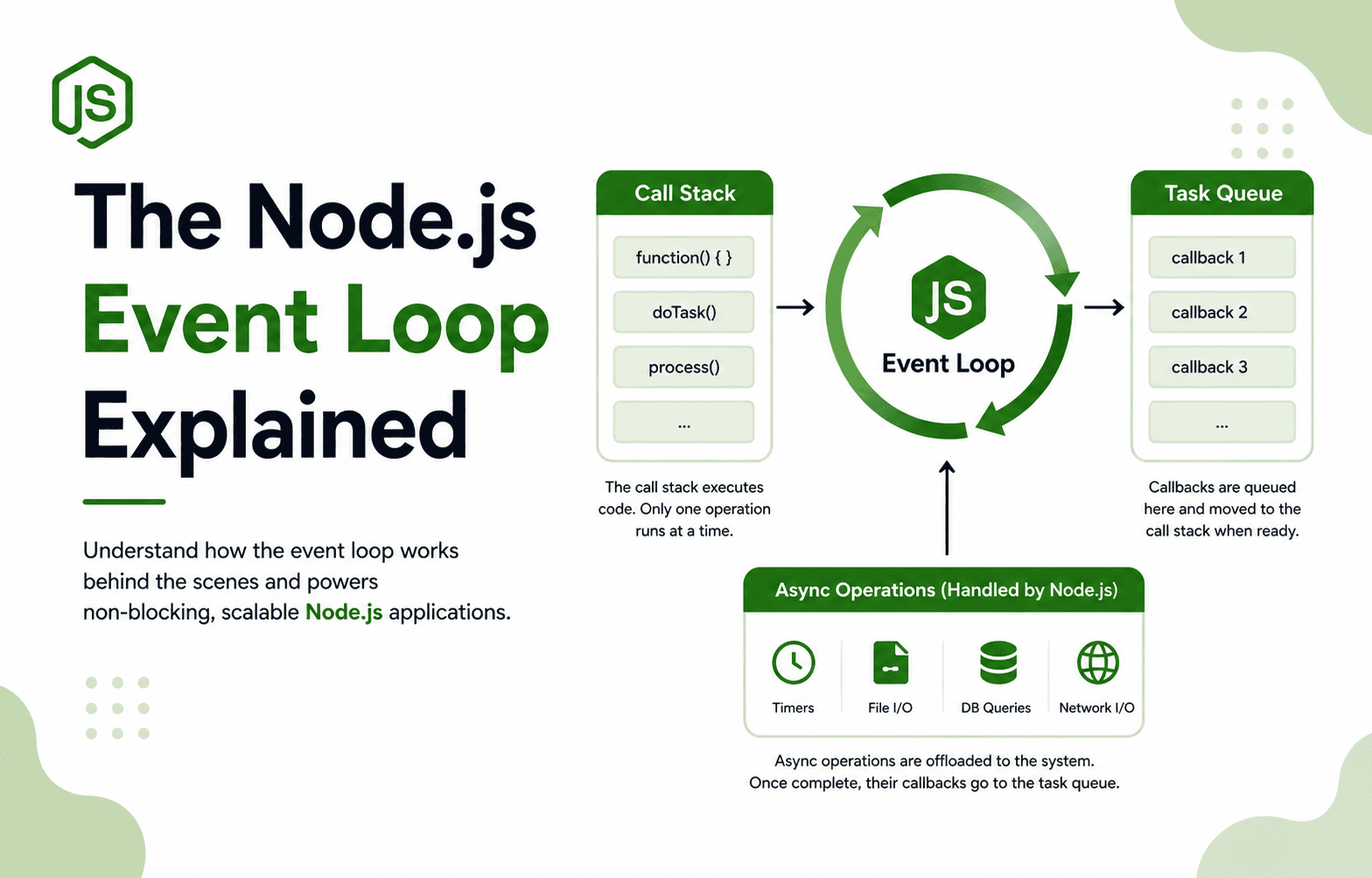
How Git Works Internally
Have you ever wondered what actually happens when you type git init? A hidden folder named .git suddenly appears, and your project seems to gain a memory. From that moment on, Git starts tracking your work — but how?
Most developers learn Git as a list of commands to remember: add, commit, push, pull. While that works, it often makes Git feel like a magic box. In reality, Git is a simple and logical system. Once you understand what happens behind the scenes, Git becomes predictable, powerful, and much easier to control.
Git: Behind The Scene
git init: Creates the Brain of Git
- When you run:
git init
- Git creates a hidden folder called
.gitinside your project directory.

This .git folder is the entire Git repository. It contains everything Git needs to function:
Your project’s history
Information about tracked files
Commits and branches
The current state of your project
Without this folder, Git cannot track anything.
Understanding the .git Folder
What is the .git Folder?
The .git folder is the brain of your Git repository. It stores everything Git needs to track your project—history, branches, commits, and configuration. Every time you run a Git command, Git reads from or writes to this folder.
⚠️ Warning: Never modify or delete the
.gitfolder, or Git won't be able to track changes properly, and your project will immediately stop being a Git repository. It will just be a regular folder of files with no version history.
What’s Inside the .git Folder?

Here are the key parts, explained simply:
| File / Folder | What It Does and Stores |
|---|---|
objects/ |
Stores all Git data (files, folders, commits) |
refs/ |
Stores pointers to branches and tags |
HEAD |
Tells Git which branch you’re on |
index |
The staging area |
config |
Repository-specific settings |
Why the .git Folder Matters
It gives Git memory
It enables time travel through commits
It makes branching fast and lightweight
It keeps data safe using hashes
Git Objects: Blob, Tree, Commit
Everything in Git is built from just three object types. These objects work together to represent a complete snapshot of your project at any point in time.
Blob (Binary Large Object)
A blob stores the content of a file.
It contains only the file data
It does not include the filename or folder information
Tree
A tree represents a directory.
Stores filenames and folder structure
Points to blobs (files) and other trees (subfolders)
Records file permissions
Think of a tree as a folder where blobs exist as files.
Commit
A commit connects everything together.
Points to a root tree (the project snapshot)
Stores the author, date, and message
Links to one or more parent commits
A commit represents one saved version of your project.
How They Work Together
Each commit points to a tree, which points to blobs and other trees. This structure allows Git to reuse unchanged data and stay fast.
Commit
└── Tree (root folder)
├── file1.txt → Blob
├── file2.txt → Blob
How Git Tracks Changes
Git tracks changes by saving copies of your files and connecting them together. It does not remember line-by-line changes. Instead:
It takes a snapshot
Stores references
Reuses unchanged objects
Git Working Areas

Working Directory is an area where you actually work.
The staging area is a temporary holding place for changes.
The repository is where Git stores all commits. This is Git’s long-term memory.
What happens internally during git add and git commit
When you run:
git add file.txt
Git does:
Reads the file’s content
Creates a blob object from that content
Stores the blob in
.git/objects/Updates the index to point to this blob
At this point:
The change is staged
Nothing is committed yet
History has not changed
Note: Think of
git addas preparing a snapshot, not saving it.
When you run:
git commit -m "message"
Git now turns the staged snapshot into history:
Git reads the index
Creates tree objects that represent folder structure
Creates a commit object that:
Points to the root tree
Stores the message, author, timestamp
Links to the previous commit (parent)
Moves the current branch pointer to this new commit
Note: Your snapshot is now permanent.
How Git Uses Hashes to Ensure Integrity
Git uses hashes to make sure your data is safe, unchanged, and trustworthy.
What Is a Hash? (In Git Terms)
A hash is like a fingerprint for data.
Git takes some content (a file, folder, or commit)
Runs it through a math function (SHA-1 or SHA-256)
Produces a unique string like:
a1b2c3d4...
Note: 1. Same content = same hash
2. Changed content = completely different hash
How Git Uses Hashes
1. Every Object Gets a Hash
Git gives a hash to:
Files (blobs)
Folders (trees)
Commits
The hash is used as the name and ID of that object.
2. Commits Are Linked by Hashes
Each commit:
Has its own hash
Stores the hash of its parent commit
Commit C → hash of Commit B → hash of Commit A
If any commit is changed:
Its hash changes
Every commit after it breaks
Building a Mental Model
Instead of memorizing Git commands, it’s more helpful to visualize how Git organizes your work.
Working Directory
Your sandbox where you edit and experiment with files.Staging Area (Index)
A draft of your next snapshot. This is where you decide exactly what will be saved.Object Store
Git’s permanent library inside the.gitfolder, holding every version of every file ever saved.
When you create a commit, Git doesn’t store a list of line-by-line changes. Instead, it saves a snapshot of your entire project exactly as it looks at that moment.
Behind the scenes, Git stores file content as blobs and identifies them using hashes. If a file hasn’t changed between two commits, Git doesn’t save it again—it simply points both commits to the same existing blob. This smart reuse of data is what makes Git fast, efficient, and reliable.
Keep Learning 🚀
Now that you’ve explored how Git works under the hood, it’s time to put that knowledge into practice. Understanding the internals gives you confidence—but using Git regularly is how it truly clicks. Check out these guides to continue your journey:
Why Version Control Exists: The Pendrive Problem
Ever wondered why tools like Git were created in the first place? This post explains the real-world problems version control solves and why it’s essential for modern development.
Git for Beginners: Basic and Essential Commands
Ready to start coding? This guide walks through the must-know Git commands every developer uses in their daily workflow, explained clearly and practically.
🔗 Connect with me:
LinkedIn | GitHub | X (Twitter)